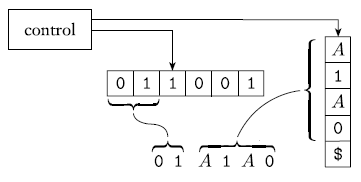
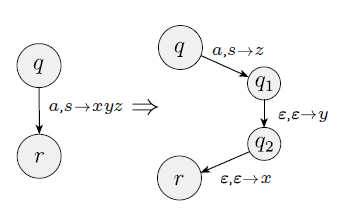
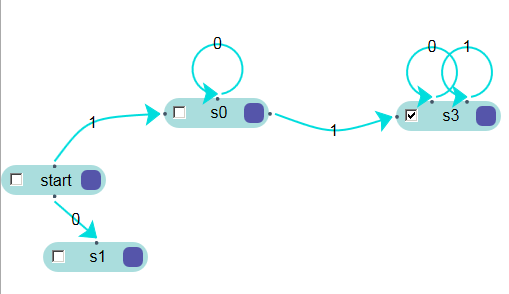
exercise 2.9
Give a context-free grammar that generates the language
A = {aibjck| i = j or j = k where i, j, k ≥ 0}.
Is your grammar ambiguous? Why or why not?
Answer
S = D|C|ε
D = Bc|Dc
C = aA|aC
B = aBb|ε
A = bAc|ε
The grammar is ambiguous because we can build two different trees if the number of as, bs, cs are the same: in this case we can consider pairs of abs and then cs or pairs of bcs and then as as prefixes.