Formalismi e cavolate
Le matrici spaventano, questo da sempre.
Però se si fanno gli esempi giusti, tutto sommato (∑) non sono neanche impossibili.
Le matrici spaventano, questo da sempre.
Però se si fanno gli esempi giusti, tutto sommato (∑) non sono neanche impossibili.
Per ognuna delle seguenti variabili si dica se si tratta di una variabile quantitativa (discreta o continua) o qualitativa (nominale o ordinale):
Il docente di un corso universitario ha raccolto alcuni dati sugli studenti che hanno sostenuto il suo esame. La tabella riporta i dati relativi ai primi quattro studenti.
| Voto | Anno di corso | Residenza | Diploma Sup. Frequentante |
|---|---|---|---|
| 28 | I | Treviso | Liceo S |
| 21 | IV | Venezia | Ist. Tecnico N |
| 18 | I | Verona | Ist. Comm. S |
| 21 | II | Padova | Ist. Prof. S |
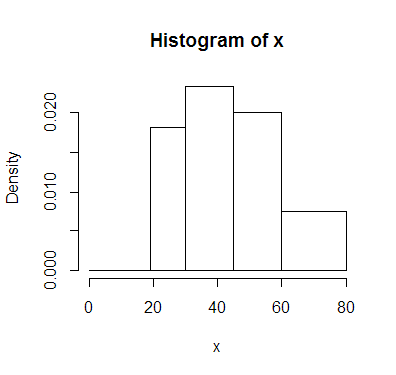
In un gruppo di 20 persone sono state rilevate due variabili, il sesso e l'età
47 61 38 40 26 41 49 65 53 55 F M M M F M F F M F 30 23 34 33 40 21 65 32 47 50 M F M F M M M F F F
| freq. ass | f. rel. | % | ass. cum | rel. cum | dens. | |
|---|---|---|---|---|---|---|
| 19-29 | 3 | 0,15 | 15 | 3 | 0,15 | 0,3 |
| 30-44 | 8 | 0,4 | 40 | 11 | 0,55 | ˜0,57 |
| 45-59 | 6 | 0,3 | 30 | 17 | 0,85 | ˜0,43 |
| 60+ | 3 | 0,15 | 15 | 20 | 1 | 0,6 |
Grafico:


L'assistenza tecnica di un rivenditore di computer ha registrato le richieste di intervento in un particolare giorno. Il risultato è stato:
H,H,M,S,H,M,M,S,H,S,S,M,H,M,M,S,M
dove H=problemi hardware, S=problemi software, M=guasto monitor.
| F. ass. | F. rel | |
|---|---|---|
| H | 5 | ˜0,29 |
| S | 5 | ˜0,29 |
| M | 7 | ˜0,41 |
Nella tabella sottostante sono riportati i consumi (in milioni di tonnellate) di risorse naturali impiegate nell'economia italiana nel quinquennio 2000-2004 e le importazioni delle medesime risorse nello stesso arco temporale.
2000 2001 2002 2003 2004 Fabbisogno 2.357 2.295 2.214 2.077 2.184 Importazioni 329.028 330.035 334.807 343.784 360.282
Il responsabile della sicurezza di una grossa azienda ha rilevato il numero di tentativi di intrusione bloccati ogni giorno durante i primi 14 giorni del mese:
56 47 49 37 38 60 50 43 43 59 50 56 54 58
Dopo aver cambiato le impostazioni del firewall, le intrusioni bloccate nei 20 giorni
successivi sono state
53 21 32 49 45 38 44 33 32 43 53 46 36 48 39 35 37 36 39 45
Al fine di valutare l'efficacia delle nuove impostazioni, si confrontino il numero di tentativi di intrusione bloccati prima e dopo il cambio, calcolando il summary dei dati, tracciando i boxplot appaiati e commentando i risultati ottenuti.
I dati seguenti rappresentano il numero di registrazioni di nuovi account in dieci giorni consecutivi ad un sito di vendite online:
43 37 50 51 58 105 52 45 45 10
Un provider vuole valutare il carico della sua rete e registra il numero di utenti (in migliaia di persone) connessi contemporaneamente in 50 luoghi:
17.2 22.1 18.5 17.2 18.6 14.8 21.7 15.8 16.3 22.8 24.1 13.3 16.2 17.5 19.0 23.9 14.8 22.2 21.7 20.7 13.5 15.8 13.1 16.1 21.9 23.9 19.3 12.0 19.9 19.4 15.4 16.7 19.5 16.2 16.9 17.1 20.2 13.4 19.8 17.7 19.7 18.7 17.6 15.9 15.2 17.1 15.0 18.8 21.6 11.9
Ω rappresenta l'insieme dei possibili risultati. La probabilità di tutti gli eventi che appartengono a Ω è 1.
ω rappresenta un elemento dell'insieme Ω, cioè l'esito di un singolo evento.
è l'insieme complementare di Ω, cioè un evento impossibile. Qualunque insieme con una "barretta" sopra è l'insieme degli esiti diversi dall'insieme rappresentato. Si può rappresentare anche con 1 - P(A), cioè 1 meno la probabilità che si verifichi un evento di A
P(A), con A ⊆ Ω è la probabilità che si verifichi uno degli eventi dell'insieme A.
P(Ai) è la probabilità che si verifichi l'i-esimo elemento dell'insieme A. A volte, senza tirare in ballo l'insieme A, si indica con pi
Si definiscano formalmente le relazioni O, Ω, Θ, o, ω e si dimostri la verità o la falsità di ciascuna delle seguenti affermazioni, giustificando formalmente le risposte:
O(f(n)) = {g(n) : ∃ c > 0, n0 ≥ 0, g(n) ≤ cf(n) ∀ n ≥ n0}
O(f(n)) significa che esiste una funzione g(n) tale che, data una costante c maggiore di zero e un parametro zero n0 maggiore o uguale a zero, g(n) è minore o uguale a f(n) per la costante per ogni n maggiore o uguale a n0.
Ω(f(n)) = {g(n) : ∃ c > 0, n0 ≥ 0, g(n) ≥ cf(n) ∀ n ≥ n0}
Analogamente, o(f(n)) = {g(n) : ∃ c > 0, n0 ≥ 0, g(n) < cf(n) ∀ n ≥ n0} e ω(f(n)) = {g(n) : ∃ c > 0, n0 ≥ 0, g(n) > cf(n) ∀ n ≥ n0}
Θ(f(n)) = {g(n) : ∃ c1 > 0, c2 > 0, n0 ≥ 0, c1f(n) ≤ g(n) ≤ c2f(n) ∀ n ≥ n0}
ovvero, scelte due costanti diverse e maggiori di zero, per una costante vale O(f(n)) e per l'altra vale Ω(f(n)).
Vero, poiché per la definizione di Θ, Θ(nk) = {g(n) : ∃ c1 > 0, c2 > 0, n0 ≥ 0, c1f(n) ≤ g(n) ≤ c2f(n) ∀ n ≥ n0}.
Asintoticamente, i termini di grado inferiore a k si possono omettere, perché per ogni h < k, si ha che
Dunque, in un polinomio nella forma cink+ciink-1+ciiink-2+ ... + cin, basta considerare il termine di grado più alto (cink) e prendere un c1 < ci e un c2 > ci
L'uguaglianza è vera se, per la definizione di O(n), n ≤ n log log n; dividendo entrambi i termini per n, si ottiene che 1 ≤ log log n, che è vero per tutti gli n ≥ e^2
n1+ε si può scrivere anche n * nε, in questo modo è possibile dividere per n entrambi i membri. L'uguaglianza è verificata se log log n ≤ nε per ogni ε > 0.
L'uguaglianza si può dire verificata se è vero che:
Ma applicando de l'hôpital, vediamo che
che tende a +∞.
La risposta alla domanda è quindi che non è possibile generalizzare l'equivalenza per ogni ε > 0.
Vero, è la proprietà della simmetria trasposta.
Falso.
Per definizione (condizioni al contorno omesse), ω(f(n)) = {g(n) > cf(n)} e O(g(n)) = {f(n) ≤ cg(n)}, quindi g(n) > cf(n) ∩ f(n) ≤ cg(n) ⇒ f(n) < cg(n), che è esattamente ω(f(n)).