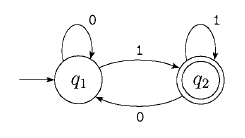
Operatori regolari
Union: A ∪ B = {x|x∈A or x∈B}
Concatenation: A ○ B = {xy | x∈A and y∈B}
Star: A* = {x1, x2, x3,...xk | k ≥ 0 and each xi∈A }
Inoltre si definisce per prassi ε stringa vuota (in maniera simile a quello che in SQL è NULL)
La prova dell'unione di A con B è data dalle seguenti cinque considerazioni:
- Gli stati possibili sono dati dal prodotto cartesiano degli stati A × B: Q = {(r1, r2) | r1∈A and r2∈B}
- Σ per ora lo consideriamo un unico dizionario per entrambe le macchine
- δ è una funzione definita su una coppia di stati alla volta: δ((r1, r2), a) = (δ(r1, a), δ(r2, a)). Ovviamente lo stato restituito è un elemento di Q, che a sua volta è costituito da "coppie".
- q0 = (q1, q2)
- Il risultato è un F = (F1 × Q2) ∪ (F2 × Q1)
Nota: il risultato NON è F1 × F2, perché questo rappresenterebbe l'intersezione dei due automi, e non l'unione, perché entrambi gli stati di uscita dovrebbero essere validi.